High Performance Computing Market Size, Share & Forecast 2026–2032
Report Highlights
- ✓Market Size 2024: $52.4 billion
- ✓Market Size 2034: $138.7 billion
- ✓CAGR: 10.2%
- ✓High performance computing (HPC) encompasses supercomputers, clusters, and parallel processing systems used for computationally intensive workloads including AI training, climate modeling, genomics, and financial simulation. It spans hardware, software, and cloud-delivered HPC services.
- ✓Leading Companies: Hewlett Packard Enterprise, IBM, Dell Technologies, Fujitsu, Lenovo
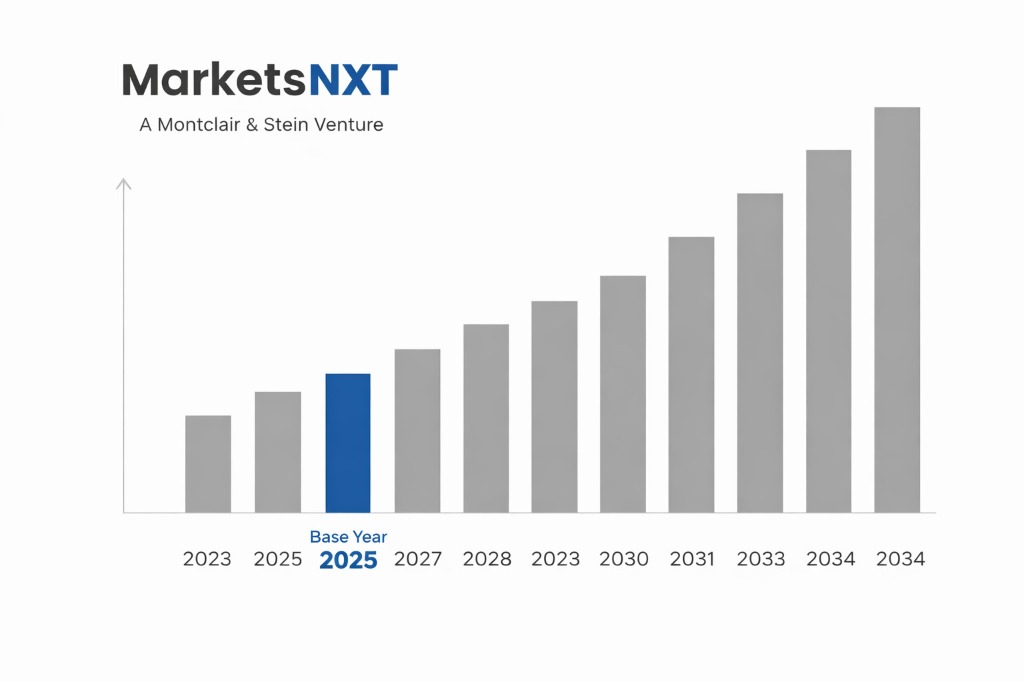
- ✓Base Year: 2025
- ✓Forecast Period: 2026–2034
Analyst Recommendation — Prioritize Accelerator-Native Infrastructure: Buyers and investors must commit to NVIDIA H100/H200 or AMD MI300X accelerator-native infrastructure before Q3 2026, as allocation lead times now exceed 18 months and facilities that delay will cede competitive simulation capacity to rivals for the remainder of the decade.
Who Controls the High Performance Computing Market — and Who Is Challenging That
Hewlett Packard Enterprise holds the single strongest position in installed HPC infrastructure, underpinned by its Cray supercomputer heritage and the dominant deployment at Oak Ridge National Laboratory's Frontier system — the world's first certified exascale machine at 1.1 exaflops. HPE's competitive moat combines decades of interconnect engineering, its Slingshot fabric technology, and deep integration with U.S. Department of Energy procurement cycles. IBM reinforces its position through hybrid cloud HPC deployments and Power10 processor architecture optimized for AI-adjacent workloads, while Lenovo has quietly captured over 30% of global TOP500 systems by unit count, leveraging cost-competitive Neptune direct water cooling to win European national lab contracts.
NVIDIA is the single most disruptive challenger to the established hardware order. Its H100 and H200 GPUs have become the mandatory compute substrate for any facility running large-scale AI training alongside traditional simulation, giving NVIDIA effective pricing power over entire data center refresh cycles. AMD's MI300X accelerator is the credible alternative, and several national HPC centers in Germany and Japan are actively evaluating AMD-based clusters to reduce single-vendor GPU dependency. The competitive order shifts decisively if AMD achieves software stack parity with NVIDIA's CUDA ecosystem — a milestone the ROCm 6.x roadmap is targeting by 2026.
High Performance Computing Dynamics: How the Market Operates Today
The HPC market operates through three distinct procurement channels: government-funded national laboratory tenders, enterprise direct procurement, and cloud-delivered HPC-as-a-service contracts. National lab tenders, which represent the highest-value individual contracts, are multi-year competitive processes where system integrators like HPE, Lenovo, and Fujitsu bid against detailed technical specifications covering peak flops, energy efficiency, and interconnect bandwidth. Enterprise procurement increasingly flows through reseller-led configurations combining off-the-shelf GPU nodes with proprietary storage from NetApp or IBM Spectrum Scale. Pricing mechanisms remain largely project-specific, with total contract values for exascale-class systems routinely exceeding $500 million including multi-year maintenance.
The market is in active consolidation at the system integrator tier, while the accelerator component layer is bifurcating between NVIDIA and a growing AMD challenger position. Cloud HPC delivered by AWS (via HPC6a and Hpc7g instances), Microsoft Azure (HBv4 series), and Google Cloud (A3 clusters) is restructuring the sub-exascale segment by converting capital expenditure into operational expenditure for mid-tier enterprises. Regulatory shifts — particularly the U.S. CHIPS Act directing $280 million specifically toward HPC R&D facilities — are actively pulling forward government procurement timelines and creating urgency in the domestic supply chain for advanced cooling and power delivery infrastructure.
High Performance Computing Demand Drivers
The single largest demand driver is the explosion of generative AI and large language model training workloads, which require HPC-class infrastructure at a scale that enterprise GPU clusters cannot economically address. OpenAI's GPT-4 training reportedly consumed over 25,000 A100 GPUs for months — a workload profile that is now table stakes for any frontier AI lab, pharmaceutical company running protein structure prediction, or financial institution operating real-time Monte Carlo risk simulation. Every new foundation model generation requires roughly 4x the compute of its predecessor, creating a structurally compounding demand curve that outpaces general IT infrastructure refresh cycles.
The second driver is government-mandated national competitiveness investment in sovereign HPC capacity. The European High Performance Computing Joint Undertaking (EuroHPC JU) has committed over €7 billion to deploy pre-exascale and exascale systems across member states including LUMI in Finland and MareNostrum 5 in Spain. In parallel, Japan's RIKEN Center for Computational Science operates the Fugaku system, while China continues deploying classified national supercomputers despite U.S. export controls on advanced semiconductors. Climate modeling mandates under IPCC reporting frameworks are a third structural driver, requiring petascale simulation capacity at meteorological agencies in more than 40 countries that currently lack it.
Restraints Limiting High Performance Computing Growth
The most binding near-term constraint is semiconductor supply chain concentration. Advanced GPU and CPU production for HPC is entirely dependent on TSMC's 3nm and 4nm nodes in Taiwan, creating a single-point geopolitical risk that is not resolvable within the forecast period. U.S. export controls under BIS Entity List restrictions have already blocked Nvidia H100 and A800 shipments to China, fragmenting the global addressable market and forcing Chinese operators including Biren Technology and Hygon to develop domestic alternatives that trail TSMC-manufactured parts by two or more performance generations. This bifurcation reduces total system-level interoperability and raises integration costs for multinational HPC deployments.
Power infrastructure and cooling capacity represent the second critical structural restraint. A single modern exascale-class HPC facility requires between 20 and 40 megawatts of dedicated power, and grid upgrade lead times in the U.S. and Europe regularly exceed five years. The Frontier system at Oak Ridge consumes 21 MW under peak load, and the next generation of zettascale-class proposals would require 50–100 MW — a threshold that most existing national lab sites cannot support without major utility investment. This constraint disproportionately affects new entrants and emerging-market national HPC programs that lack the existing grid infrastructure of established U.S. Department of Energy sites.
High Performance Computing Opportunities
The convergence of HPC and AI in pharmaceutical drug discovery represents a high-value, near-term accessible opportunity. Schrödinger's molecular dynamics platform and Recursion Pharmaceuticals' phenomics pipeline both require sustained petascale compute, and the addressable market for dedicated pharma HPC capacity is expected to double between 2024 and 2028 as AI-driven clinical trial design becomes standard practice at top-20 pharmaceutical companies. Vendors that offer pre-configured, validated HPC appliances tailored to life sciences workflows — combining NVIDIA DGX hardware with purpose-built molecular simulation software stacks — will capture disproportionate margin relative to general-purpose cluster vendors.
Cloud-native HPC delivered as managed service for mid-market engineering and manufacturing firms is the second major opportunity. Companies with 500 to 5,000 employees performing finite element analysis, computational fluid dynamics, or seismic modeling currently cannot justify on-premise HPC capital expenditure, making AWS ParallelCluster, Azure CycleCloud, and Google Cloud's HPC toolkit the default entry point. The managed HPC-as-a-service segment is growing at approximately 18% annually, outpacing the broader market, and independent software vendors including Ansys, Siemens Simcenter, and Altair are actively partnering with cloud providers to deliver pre-licensed, burst-compute environments that eliminate the traditional barriers of scheduler configuration and software licensing complexity.
Market at a Glance
| Metric | Detail |
|---|---|
| Market Size 2024 | $52.4 billion |
| Market Size 2034 | $138.7 billion |
| Growth Rate (CAGR) | 10.2% |
| Most Critical Decision Factor | GPU accelerator availability and interconnect performance |
| Largest Region | North America |
| Competitive Structure | Consolidated hardware, fragmented services layer |
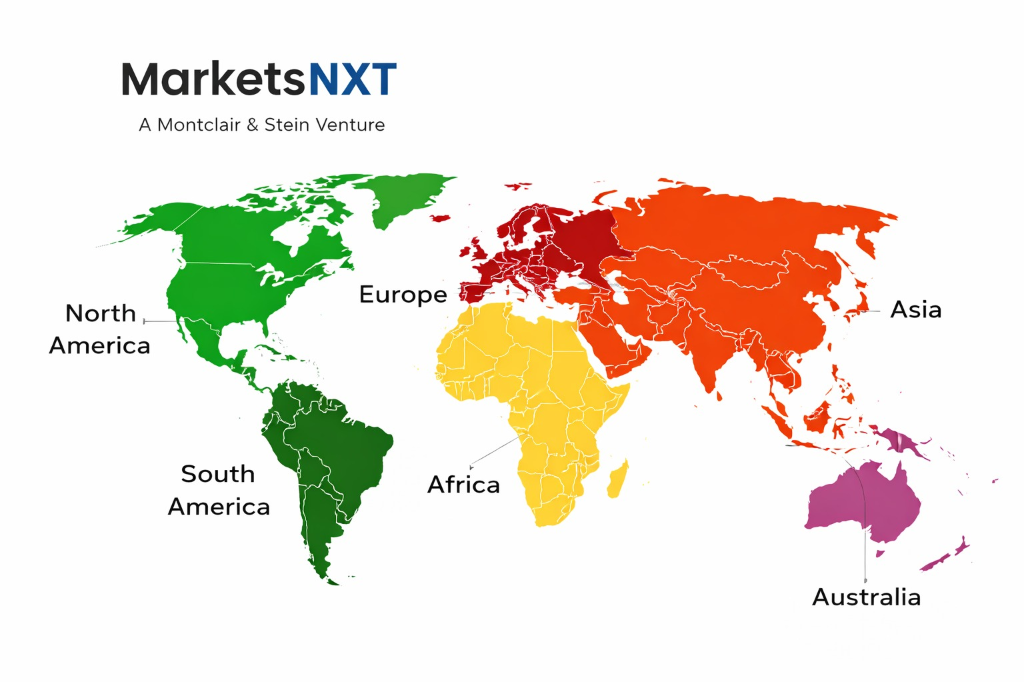
High Performance Computing by Region
North America dominates the global HPC market, accounting for an estimated 42% of total revenue in 2024, driven by U.S. Department of Energy national laboratory investment, DARPA-funded research programs, and hyperscaler AI infrastructure buildout by Google, Microsoft, and Amazon. The United States alone hosts six of the world's top ten supercomputers by performance. Europe is the second-largest region, with EuroHPC JU deployments accelerating adoption in Finland, Spain, Germany, and Italy; the region is distinguished by a strong emphasis on energy-efficient liquid cooling architectures driven by stringent EU data center sustainability regulations taking effect from 2025 onward.
Asia Pacific is the fastest-growing HPC region, projected to expand at a CAGR of 13.1% through 2034, led by Japan's continued investment in post-Fugaku system planning, South Korea's national AI computing initiative, and India's National Supercomputing Mission targeting 45 petaflop aggregate capacity across academic institutions. China represents a structurally constrained but still substantial market; despite U.S. semiconductor export controls limiting access to leading-edge accelerators, China's domestic HPC deployment continues through state-funded programs using Sunway and Matrix-2000 processors. Latin America and the Middle East and Africa remain nascent but are seeing early national HPC deployments in Brazil, Saudi Arabia, and the UAE tied to sovereign AI strategy announcements made in 2023 and 2024.
Leading Market Participants
- Hewlett Packard Enterprise
- IBM Corporation
- Dell Technologies
- Lenovo Group
- Fujitsu Limited
- NVIDIA Corporation
- Intel Corporation
- Advanced Micro Devices (AMD)
- Microsoft Corporation
- Amazon Web Services
Competitive Outlook for High Performance Computing
Over the next five years, the HPC competitive structure will bifurcate sharply between the sovereign infrastructure tier — dominated by HPE, Fujitsu, and Lenovo in government and national lab contracts — and the cloud-delivered HPC tier, where AWS, Microsoft Azure, and Google Cloud will consolidate share by bundling HPC capacity with AI platform services. The system integrator tier will face margin compression as GPU commodity pricing stabilizes post-2026 and procurement bodies increasingly specify open-standard interconnects like UCIe and Ethernet-based alternatives to proprietary fabrics, reducing the technical differentiation that historically justified premium contract pricing for incumbents like HPE's Slingshot.
The single most important competitive development to monitor is whether AMD's ROCm software ecosystem achieves genuine production-grade parity with NVIDIA CUDA by the end of 2026. If AMD delivers on the MI350X roadmap and ROCm reaches full compatibility with the top 50 HPC simulation codes tracked by the HPC Advisory Council, the effective GPU duopoly collapses and system integrators gain real procurement leverage to negotiate down NVIDIA's currently dominant hardware margins. That outcome would accelerate total HPC deployment volumes by unlocking mid-tier government programs currently stalled on budget approval, representing an incremental $8–12 billion in addressable procurement through 2030.
Market Segmentation
By Component
- Servers and Compute Nodes
- Storage Systems
- Networking and Interconnects
- Software and Middleware
- Services
By Deployment Mode
- On-Premise
- Cloud-Based
- Hybrid
By End-Use Industry
- Government and Defense
- Academic and Research
- Life Sciences and Healthcare
- Banking, Financial Services and Insurance
- Energy and Oil and Gas
- Manufacturing and Engineering
By Architecture
- GPU-Accelerated Clusters
- CPU-Only Clusters
- FPGA-Based Systems
- Quantum-Classical Hybrid
Frequently Asked Questions
NVIDIA's CUDA software ecosystem, with over 4 million registered developers and 20 years of library optimization, creates a switching cost that hardware specifications alone cannot overcome. Its H100 NVLink topology also delivers 900 GB/s GPU-to-GPU bandwidth, a figure no competing interconnect architecture matches at scale today.
HPE's Slingshot high-speed interconnect and its proven systems integration capability for multi-cabinet, multi-vendor exascale deployments represent institutional knowledge that cannot be replicated quickly. The Frontier deployment at Oak Ridge is a reference architecture that directly influences Department of Energy procurement specifications for the next contract cycle.
China remains the world's second-largest HPC market by installed capacity but is now operating on a domestically constrained technology roadmap that widens the performance gap by approximately one generation per two years. Domestic vendors Biren and Hygon are the primary beneficiaries, but neither has demonstrated production-grade reliability at petascale scale.
Cloud HPC is capturing net-new mid-market demand rather than displacing existing on-premise installations at large enterprises or national labs. Latency-sensitive simulation workloads and data sovereignty requirements keep the majority of top-100 HPC sites committed to owned infrastructure through at least 2028.
The managed HPC services layer — currently fragmented among Rescale, Cornelis Networks, and regional integrators — will consolidate around the three major hyperscalers within three years as AWS, Azure, and Google absorb workflow management and scheduler tooling through acquisition. Independent HPC software vendors that resist hyperscaler partnerships face rapid margin erosion.
Frequently Asked Questions
Market Segmentation
- Servers and Compute Nodes
- Storage Systems
- Networking and Interconnects
- Software and Middleware
- Services
- On-Premise
- Cloud-Based
- Hybrid
- Government and Defense
- Academic and Research
- Life Sciences and Healthcare
- Banking, Financial Services and Insurance
- Energy and Oil and Gas
- Manufacturing and Engineering
- GPU-Accelerated Clusters
- CPU-Only Clusters
- FPGA-Based Systems
- Quantum-Classical Hybrid
Table of Contents
Research Framework and Methodological Approach
Information
Procurement
Information
Analysis
Market Formulation
& Validation
Overview of Our Research Process
MarketsNXT follows a structured, multi-stage research framework designed to ensure accuracy, reliability, and strategic relevance of every published study. Our methodology integrates globally accepted research standards with industry best practices in data collection, modeling, verification, and insight generation.
1. Data Acquisition Strategy
Robust data collection is the foundation of our analytical process. MarketsNXT employs a layered sourcing model.
- Company annual reports & SEC filings
- Industry association publications
- Technical journals & white papers
- Government databases (World Bank, OECD)
- Paid commercial databases
- KOL Interviews (CEOs, Marketing Heads)
- Surveys with industry participants
- Distributor & supplier discussions
- End-user feedback loops
- Questionnaires for gap analysis
Analytical Modeling and Insight Development
After collection, datasets are processed and interpreted using multiple analytical techniques to identify baseline market values, demand patterns, growth drivers, constraints, and opportunity clusters.
2. Market Estimation Techniques
MarketsNXT applies multiple estimation pathways to strengthen forecast accuracy.
Bottom-up Approach
Aggregating granular demand data from country level to derive global figures.
Top-down Approach
Breaking down the parent industry market to identify the target serviceable market.
Supply Chain Anchored Forecasting
MarketsNXT integrates value chain intelligence into its forecasting structure to ensure commercial realism and operational alignment.
Supply-Side Evaluation
Revenue and capacity estimates are developed through company financial reviews, product portfolio mapping, benchmarking of competitive positioning, and commercialization tracking.
3. Market Engineering & Validation
Market engineering involves the triangulation of data from multiple sources to minimize errors.
Extensive gathering of raw data.
Statistical regression & trend analysis.
Cross-verification with experts.
Publication of market study.
Client-Centric Research Delivery
MarketsNXT positions research delivery as a collaborative engagement rather than a static information transfer. Analysts work with clients to clarify objectives, interpret findings, and connect insights to strategic decisions.